How they harvest our data
It's hard to be in IT, cause your friends have no idea what you do. Engineer, product manager, QA — how does it all differ from fixing a printer in the office? (tip: you don't get $150k/year for fixing printers).
You also can't really talk to normal people about IT, because they use this industry, but they don't get it. But there's a topic you can raise with any mortal, that will get their attention: data privacy.

Disclaimer:
- this one is a biggie. I tried to add some pics and jokes so I don't mess with my readers' clip culture;
- if you're from IT — well, it would be like learning the alphabet once again. Probably you won't find anything new; if you do, that is a bad sign for your employer.
How do they gather data about us? Will VPN and incognito mode save us? Maybe we should all just pack our stuff and go into the woods and make friends with wolves and bears?
Part 1: Classification
Right to privacy in some sense consolidates all other rights as well: to vote, freedom of expression, equal opportunities, and so on. Once you lose your right to privacy you're screwed. Most of the people can easily be caught in a mind trap "I have nothing to hide, why would I care?". Common mistake. You shouldn't worry about stuff you wanna hide, you should worry about what is in plain sight.
This topic is so broad I was forced to come up with a categorization of a sort. I thought of it for no less than 3 minutes and this is the result: the most important thing is how obvious it is for an end user who stores the data, what the data really is and how it is manipulated. So, 3 variables: actor, data, and manipulation. A simple 3-dimensional matrix — you remember I wrote even a dumbass will understand the article? you don't remember? Me neither. Apparently, I didn't write it.
Actor:
- immediate receiver. When you give your phone number to get a new discount card the store gets your phone number. Yes, it's the first incredible insight from the article, thanks, Dan — you're welcome, my fellow reader.
- shadow receiver. Is it obvious though that in that case your phone number will be sold to anyone else? Would you like it if Google and Facebook found out you are a regular customer of a brothel called "Tight flower bud"? Have no doubt, they will buy that shit. You're only starting to type "Epstein didn…" and the FBI already checks what toilet paper you use to threaten your ass using Braille writing system — all thanks to your Walmart discount card, ffs.
Data:
- stuff you give away consciously. You open another app that turns you into a cutie doggie. It asks for access to your photo gallery and camera, and you obviously allow it. What can go wrong?
- stuff you didn't mean to give away. Mmm, 3896 photos you took over the last 3 years. These photos also contain meta-tags with geo-coordinates of the place the photo was taken. So it means it is a very accurate history of your moving. Who would have thought the app gets programmatic access to all the photos and not just the one you choose.
Manipulation:
- storing. Let's get back to the photos. If you choose a photo to add a doggie face, this photo can be stored on the servers of this service for god knows how long. Nothing strange.
- calculation. But, as I said, the app also gets access to the whole gallery. Is it that obvious that the app can get a pretty accurate guess on what is your home and work addresses are based on the time and geo-location of each photo? Or that it can run every image against an ML algorithm that finds NSFW images and securely upload it to the servers? I hope your fucking doggie face was worth it.
- selling. If you don't pay for the product, you are the product. What a cliché. Instagram is free because every single person on Earth can buy ads for a very specific audience. Those who travel to beaches, who loves certain food or have a high income. Instagram calculates all of this from the enormous data set they have, and the advertiser can combine these segments however they want. Of course, once you click an ad the advertiser knows exactly what segment you are in.

- hacks or leaks. Oh, guys and gals, when we get to this I'll turn your camera on to capture how surprised you'd be. For now, just believe me: all the companies lose the data from time to time, from a small garage startup to Google, from a small accounting firm to Revenue Service of an entire country. I get chills from some of the most notorious cases, really.
Some of the bullets require some explanation (and we'll get to that!) because laymen for some reason think Big Corporations are not that bad and want good for humanity. Well, if you also think that your frustration will be very painful.
Part 2: Actors
Let's go top to bottom. Cumplucters are connected with a huge Great Internet-Network and they talk to each other using Magic Requests.
(all of it are eligible terms, I'm a pro, believe me)
When you visit someone's blog your computer makes a request to another computer and gets some response. But the response does not go directly to the server, it has a few stops on the way. Each stop has its own dangers.
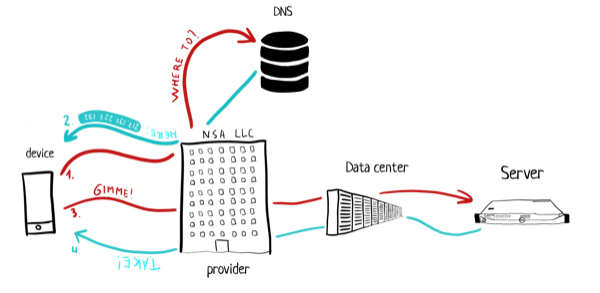
The outline is super simple, its accuracy is around 60%, but according to British scientists you are a 60% banana, so if you're very interested go check out the whole story of the request.
Device → DNS
Machines identify each other using ip-addresses — those look like 4 numbers split out with dots, like 127.0.0.1. People are not that good with numbers, we're used to strings, like dkzlv.com. We call it "domain".
God save you if you'll come telling me about ipv6.
But the computers still work — all thanks to a thing called DNS (Domain Name Server, clear, isn't it?). Think of it as a huge table in Excel that translates a domain into an ip-address.
DNS will be the first breach. The problem is that the founding fathers of the internet didn't foresee this informational revolution and they made the information exchange with the DNS completely unencrypted. Later we'll talk about transport layer security, but the idea is simple: your internet provider will always know what sites you visit. Sometimes it can even modify the answer from the original DNS if the site owner does not implement DNSSEC.
Answering your question: yes, your provider knows you visit the site, which makes you sweat like a dog.
Solution: we have a few. You can use DNS-over-HTTPS (DoH) or DNS-over-TLS (DoT). There's some difference that smart people get (I really don't), but you shouldn't dive into these details.
You remember those tech guys who came to your house that set up the internet? They should have given you a piece of paper and said "don't lose this". You immediately threw it in the garbage after that, AND YOU DID RIGHT. It had your provider's DNS there, and that tech guy set up your router to use it. "It helps you with speed" — they said. "Insecure shit" — we understand. They do not support DoT and unlikely they will ever support it, because why would they.
Try to use independent DNS-servers. I recommend using Cloudflare DNS with a cool ip-address: 1.1.1.1. It's free, fast and they promise a zero-logs policy, so they don't save anything about your dirty little secrets. They have apps for smartphones, that setup everything magically, so use them, otherwise it's kind of difficult to setup.
It gets trickier for desktops. First, you need to setup a DNS on the OS level, and then turn on an experimental DoH support in the browser.
Device → Provider → Datacenter → server
There are two types of connections: secure and not secure. You'll get a notification about an insecure connection from the browser if it's not an old piece of mammoth shit. If it's not an old piece of black rhino's shit, which got extinct in 2013, it will even ask you to think carefully if you should use this site at all.
If you see a notification about an insecure connection, you'd be safer to just close this site and do nothing there. Believe me, this site may be as bad as having unprotected sex with a partner that has radial red stripes spreading from their genitalia.

Insecure connections have no real vulnerabilities, except a small one: every single intermediary has complete control over stuff you send and receive — so it means a complete lack of any security at all. Some mobile operators, for example, embed their fullscreen ads on insecure sites without asking any permission from site owner.
So let's talk about secure connections. I'll give you a small lecture about cryptography (no, it has near to no connection to cryptocurrencies) and how the network works so you can impress your grandma.
If you're not a Ph.D. in cryptography and haven't launched an ICO from school's canteen, it good enough to know there are two types of encryption: symmetric and asymmetric. Symmetric is the one that has a single key for both encryption and decryption. Asymmetric one is where you use one key to encrypt stuff (it's called public key) and another key to decrypt it (it's called private key).
Nobody really knows how the math works (like nobody really knows how so heavy-looking planes manage to fly the sky), but Diffie-Hellman key exchange protocol that powers all this voodoo-shenanigan is safe enough for you to send sacred cat photos to your family.
So, we use both types of encryption. It's rather boring to read, so I wrote a play that illustrates the whole process.
Characters:
Jimmie: young Alamaba fella having troubles with girls for some strange reasons.
Hannah: just a girl I added here to make a full picture.
Jimmie's phone: the device that sends messages.
Tinder: an app. (any similarities to reality are entirely coincidental)
Tinder's server: the server that receives messages.
Act 1
Jimmie types a message to Hannah in Tinder
Jimmie's phone (talks to Tinder's server_): Hi there, good fellow. My guy wants to write yet another message (signs). Let's do this quickly and securely. I know HTTPS.
Tinder's server: Hi there, pal. Yeah, I get it. I know HTTPS as well. Here's the plan: first, I'll send you my public key, please encrypt everything with it. Second, please send me some encrypted gibberish so I can generate a symmetric key from it, because symmetric encryption works much faster than the asymmetric one, dear reader.
The forth wall breaks
Tinder's server sends the public key
Jimmie's phone and Tinder's server shake each others' hands
Jimmie's phone: Your public key is good. Ok, here's my gibberish. I've generated a key from it, it looks more or less like this.
Jimmie's phone sends encrypted gibberish and an approximate look of the generated key
Tinder's server: Ok, I decrypted it, looks gibberishy enough. I've generated a symmetric key as well and it looks like yours! That's ok, I'm finished.
Jimmie's phone: I'm finished too.
Now Jimmie's phone and Tinder's server use the same symmetric key that was never sent in plain text over the network, so the communication is secure
Act 2
Jimmie (finished typing): wanna play with my dong???
The end
I've simplified a process a little bit (certification centers, symmetric key's hash, etc.). If you're a really interested nerd go ahead and read about TLS handshake in the same article about network.

When having a secure connection every intermediary still sees what server you talk to (a certain ip-address), but this information is not enough for any normal analysis, since the whole data exchange is encrypted and the encryption is unique because the key is generated for each person individually. I think, there are some complex and uncertain heuristics, that can allow the intermediary to guess what type of content you're seeing. Like, if you've been streaming some stuff from pornhub.com, one can be rather sure you're downloading a lot of PDFs with knitting patterns. But you shouldn't worry about those heuristics, they are very approximate.
Solution: do remember about unprotected sex insecure connection. Everything goes as plaintext there: card data, content, address, form data, photos… If you see this notification, just close the site. Site owners that cannot setup HTTPS in 2020 (AND RISING) should be ashamed.
If you also don't want intermediaries to know the ip-address, you should use VPN. It is illegal to publish VPN instructions in my country, but can't say I really care, so I'll add that Cloudflare's app, that I advertised above, also has s free VPN there. But you shouldn't put all the eggs in the same basket, so try to use other services, like Tunnelbear. Works like charm.
Final page → ???
So we've come to the worst part of the post. Everything that was before is actually a big joke compared to this because here we have a 4-layer minefield. Even the best of us screw up here constantly.
So as you imagine there's no magic in cumplucters. If you dig into this cesspool you'll see that every insecure and dumb solution had a good meaning behind it. It's just like the nuclear power utopia that turned into rather fucked up events for two big Japanese cities in 1945.
If two machines talk, there are requests. If you send nudes to some anonymous person on the internet, there are also requests, that some program does without you knowing. And the final page in the browser — well, it also can send requests.
The anatomy of a request
So you came on the "root" page — like https://dkzlv.com/ — and it is a separate request. If you want to go to a certain post — like https://dkzlv.com/<mark>en/posts/how-they-harvest-data</mark> — it is a separate, new request.
A long time ago you couldn't identify users between requests. But those times are over. The guys behind all the standards understood that they needed a way to save cart state between requests in a typical internet-store. As usual, the road to hell is paved with good intentions. They came up with the notorious cookies, of which you've been getting warnings of late a lot.
A cookie is essentially a big line of text, that has key-value pairs and looks like this:
TOKEN=0d8152ec62c144bdbe9c96e366112aca; FAV_PRON_GENRES=4,8,15,16,23,42; CHECKOUT_STATE=0;
They decided that server could ask the browser to save this text in connection to a certain host, and then the browser would send all the consecutive requests with this line of text. The procedure is rather simple:
- you enter your login and password on a site of yet another startup that makes corrective glasses for turtles;
- the server checks if data matches, and if so it creates a unique line of text (like
7d8921806f9b4d3baec79c489237acfa) and saves it with an association to the user. If anybody knows this line of text, it should be this user; - server passes this line of text down to the browser as a cookie;
- all consecutive requests are sent with it.
Hooray! Now we have an unambiguous and certain identification, so we can save cart state on the server and it will persist transitions between pages. The problem is kinda solved, but privacy was a victim of this small change.
So when exactly Google finds out about your purchase history? Let's find out — we're about to enter the phase of galloping growth of internet ads.
JavaScript and dynamism
At first there was nothing. Then the internet came. All the pages were static. If you clicked on a link, it would result in a complete reload. There were no animations at all. No banners. No auto-play music on pages. There were no such blogs, that would make your new Macbook Pro run the fans as if it was a 3D shooter. Those were the times.
But they thought we should add some dynamism. Dynamism cannot be possible without a programming language, that's why they came up with the best language in the world — Cmm CEnvi Mocha LiveScript JScript JavaScript (it took more that one try to get to perfection). JS adds the said dynamism. What is it? Well, try to click this button:
Taking about blogs with animations, am I right? Well, then, a long time ago, in the previous millennium, there was no such beautiful dynamism. You can see that the invention was worth it, wasn't it?
JavaScript is a full-featured programming language, and a developer can access a lot of stuff. It can send requests to any server in the world (with some exceptions), save data between visits, gather data from accelerometer and gyroscope, catch all the keystrokes from the keyboard. It also can do a few things if you give it specific permission: sending push-notifications, read your geolocation, work with files, USB-ports, Bluetooth devices, read data from your camera and microphone. Long story short, a lot of possibilities.
Browsers do have some poor ways of protecting your privacy but keep in mind that browser developers don't give a shit about your privacy, so most of the protections can be worked around by anyone who has a functioning brain.

Browsers have protection against setting the so-called third-party cookies, which are cookies, that are set from some other host. If I send a request in your browser from this current page, that has "dkzlv.com" host, to google.com, cookies won't be set or sent — pRoTEctIoN ☝️ But how do these tracking scripts work without third-party scripts? They do know all of our movements, don't they? Well yes. The workaround is so simple it even disgusts me (if you're curious, here's a simple explanation, but this guy didn't push it to the end; if you use iframe and has a correct CORS setup, you can work around this problem as if it wasn't there at all).
Or browser vendors say, that if you care about privacy or have dark secrets (reading between the lines: you want to wank of on incest porno), then go ahead and use incognito mode! Yeah. Like that will protect you.
We all have fingerprints. And even though dactyloscopy is not that accurate as we're used to thinking, we're used to thinking that it somehow helps you with identification. Well, our devices also have fingerprints of a sort. 2 facts:
- I've already told you what an ip-address is. Your device (or, to be precise, your apartment or office) also has one! You should know that every request you make from a browser tells your ip-address to the server, and it doesn't matter if you use incognito mode or not. The server can get information about your country, city, district and sometimes even the building based on your ip-address alone.
- your browser gives away a lot of information. Window size, monitor size, browser, and its version, OS and its version, default keyboard language, preferred language, installed fonts, and so on. It's rather useless when you look at separate metrics, but if you combine it all we'll have a huge uniqueness of a single device. My notebook has the uniqueness of 1 in 202k other devices, fml.
Combine it with your ip-address, which is most of the time static (so it does not change over time), and for any respectable company, it is as easy to match your incognito personality with your regular one as for a toddler to take a shit into his pants.

DEMO-TIME. I've shamelessly stolen the idea here. These guys can make technology, but they lack a beautiful demonstration. But they have a thing I don't have: they'll show you every bit of data one can get from your browser, and how unique it is to their knowledge. It's a lot. But I made another demo!
Let's make a simple experiment. I'm a simple guy, I have no high education, I'm no match to those smoothie-engineers from Google. Let me try to identify you in the incognito mode. The experiment is simple:
- I'll ask you a simple yet awkward question, you should answer honestly!
- then you can open the same page in incognito mode (right mouse/open in incognito mode). You can wait a bit to confuse me (lol), but it won't help
- then do believe in smoothie engineers and do not believe me, a self-taught simple guy, they think about your privacy day and night, incognito mode to the rescue!
Additional data:
- I've added 10k unique fingerprints as extras with different answers;
- I wipe all the data every day at 00:00 GMT+0;
- data will never leave my servers. What happens in Las Vegas only goes in bad comedies.
To the question!
C'mon, sweatie, tell me what your favorite pr0n is?
I use this open sourced lib, they also have a commercial version of the same lib, which, according to their words, has 99.95% accuracy (there's a similar demo, by the way).
I don't know if it worked for you, but it works for me each time. No fails. So that is how they start wearing a tinfoil hat.
Scripts
Scripts. Scripts are everywhere. Scripts are in your phone, fridge, and TV, your vibrator and oven, automatic window roller shutter and in your audio system, in a subway train, and in your vibrator again. They are everywhere. In my blog as well.
If you want to understand why scripts are important for this topic, you need to have a deep dive into internet history. Buckle up, you're about to travel into to 2000s.
Let's add a setting.
Navigation on pictures. Comic Sans is the main font for the site. Dial-up modem cracks cozily. Internet Access Cards. Mother screaming from the kitchen that she needs the phone to talk to a friend, so "close your goddamn internet". Yahoo is the best search engine. Hotmail is the best email service. Computer clubs, where you hang out with your buddies. Your life is full of happiness.
Catalogs
We had catalogs before search engines took over. So you opened your browser in 1998, where should you go, what should you do? There was no Google yet. Yes, you should open a catalog. These were manually curated sets of sites with different topics, where you could find out the latest hot stories about Paris Hilton. Catalogs were created by then-huge and popular companies (any olds here? do you remember how cool Yahoo and Altavista were?) and they were the moderators.
You cannot rely on your opinion, you need data. How can you make a reliable guess whether an enlisted site is really popular? Catalogs should sort them by popularity. So they came up with web counters.
For an end user it looked like an image, but the devil is in the details:
- all pictures are separate downloadable resources, they are not embedded into the page, they are merely linked to it.
- if it is an external resource… you need to send a goddamn request to get it.
Yes, the end user only sees a picture with a count of visits and unique visitors; but the catalog, that generates this picture, sees everything about you: when you opened the page, what page references this counter, and, obviously, can identify you between different sites. They needed some help from webmasters to plant these counters, and the webmasters sold you easily: they were offered some basic analytics (number of visitors, most popular pages — that sort of thing) and more traffic from the catalog. That's it, you're screwed, the catalog now knows you have a thing for tall blonds. The counter is there on many sites, the catalog gets info on all the visitors and moves popular sites up the list.
But it's important to understand, that picture is a static resource. Yes, you need a request to get this picture, but it can be cached between pages (you don't need to request stuff that hasn't changed), and that's why the catalog didn't get all the visits. And still, it's not that much information at all, they couldn't get any information on user's behavior: how much time they spend on the site, how far they scroll, how deep into the site they went, what links they click, etc. This is a picture, not a script.
Search engines
Then search engines came and it all became a little bit complicated. Search engine's spider visits sites, downloads everything, and searches stuff in the saved copy. The most important question still holds: how should it understand it showed the best result for your question "how to kil meself?"? Answer: the user should disappear from the radars. It doesn't know how a user behaves on the page, how often they visit this site. It has no real data to prove the site is good. Then Google came up with a genius solution.
Web counters are lame — they don't give that much data. We need a script, and we need to inject it to as many sites as it's possible. Blackmail and soldering iron are not an option, so how can we persuade webmasters (a term from the past as well) to inject this script? Should be very useful for them. So in 2003 they launched AdSense, their own context advertizing platform. It allowed webmasters to get paid for people watching and clicking on banners on their site, they just needed to inject a simple script. A small step for the company, a huge fuckery for the whole of humanity.
The second step was to launch Google Analytics. Apart from money web devs want to know more and more about their visitors: what pages are most popular, where they came from, what the user flow is, time spent on the site, etc. Google launched their free web analytics tool: "insert my script into your site, please, do it, I want to smear my servers with your big BIG data" — Google whispered voluptuously into the ears of all the developers around grabbing them brazenly by their servers.

As we know, scripts can know a lot: what you click, how far you scroll, where you go after that, what you type on your keyboard, etc. What can go wrong at all? We're in the last part of my essay.
So who's this shadow receiver?
Anybody in the world.
According to BuiltWith 68% of the top 1M use Google Analytics. 88% of the top 10k. AdSense has a smaller penetration — 16% and 33% respectively. We're so screwed. I know, your hands shake a little bit and got really sweaty, and I'm pleased to announce the thing you're most afraid of: 93% of porno-sites has these 3d-party scripts. Google knows for sure you're aroused by the stuff that is strictly against the law in your country, whatever that is.
No-no, don't get me wrong. Google is not the only company. 40% of the top 10k sites have tracking pixels from Facebook.
Automattic (a company you've never heard of) has developed a blog engine called WordPress, and they offer site hosting for it. They handle half a billion people every month on their hosting; they also acquired erotic blog hosting called Tumblr, which has 437M visitors in 2019.
You see a cool floating set of like buttons on a site? It can be a script by AddThis guys, that have 26% in the top 10k sites.
You see cool stylish icons on the site? There's a chance they are powered by FontAwesome script, that is injected in 46% in the top 10k sites.
All these companies have some Privacy Policy, that has a lot of bullshit, that nobody reads. It can have some wild shit — like that a browser extension Grammarly, that checks your texts against some set of grammatical rules, stores your text forever, any of their employees can read it, they get unexclusive right to store, use and copy your text. I didn't come up with that. Truth be told their support agent tried to explain some of the stuff, but when these guys write "yeah, it sure looks like this, but actually we don't do this", I just giggle like crazy and put on my tinfoil hat.
You don't know it, you don't see it, but it just works. They know everything about you.

Solution
You don't know, why this mad harvest is bad yet, but believe me, it's in your best interest to stop it. You gain nothing of it.
I see a few solutions. The simplest one that works — start using Brave browser. It is identical to Chome, but it doesn't have all the tracking by Google. It's a private company led, and this is true, by Brendan Eich, the guy who created JavaScript in the first place! It has a few benefits:
- they have a very cool blocker of all the described stuff. It does not guarantee you protection against trackers and some data will still get to corporations, but it will be much much less;
- it is open-sourced. Completely. You can (but won't) go and read their source code here. In some ideal world it means that the community has reviewed the code for bad behaviors.
Please, for the name of the god, never use browser extensions. It is a legal security loophole, that will undermine all your privacy efforts. I'll tell you about it later.
What about apps?
I consciously focused on the web here and not on the apps. Why? Because compared to apps web is a safe and private haven. Apps just don't have any privacy at all:
- you can't disable some app's access to the network at all or partially. Yes, Android has separate permission to work with the network, but in my subjective opinion all the apps request it. You can do this on the web in any browser;
- you can't review what data has been sent from the app without special software; if you do install this software (Charles, for example), the app can check for it and stop doing bad stuff (read about HPKP). Should also mention, that some apps will specifically forbid you to use the app if you install this software (hey there, Facebook!). You can do this on the web in any browser and it cannot be detected;
- iOS, Linux, Mac, and Windows native apps are compiled into unreadable bytecode, Android apps are changed to barely readable condition. It is almost impossible (or very very hard) to decompile native apps into human-readable code. JavaScript can be shipped without real transformations, and even if it was transformed it is much simpler to read and understand;
- all apps have access to highly accurate advertising ID. Identification works between different apps. The web has no Ad Ids and it is quite hard to identify users between different sites (especially if you ban scripts);
- both Android and iOS are owned by techno giants, which are not really interested in your privacy. The web is not owned by anyone specifically; in reality, it is owned by a wide conglomerate of corporations and government facilities that watch each other. Google is the most powerful actor here and it has a lot of control over the web, but it's not that simple.
- apps can launch in the background without your explicit permission and do practically anything. You can't do that on the web yet (but Chrome team plans to add this in the future).
Apps hold a lot of secrets and monitor users even more.
Despite all the difficulties some research is still possible here. There are guys, called 42matters, who offer a free trial with the possibility of looking up what apps use certain SDKs (it's more or less the same as 3rd party scripts). Firebase SDK (Google's product) is used on 25k of iOS apps and 1.3M of Android apps, including Pinterest, Shazam, and Google Maps. Facebook's SDK is installed on 81k iOS apps and 383k Android apps, including Spotify, Instagram, Lyft, and Clash of Clans. Appsflyer SDK, which helps developers to accurately identify users between platforms, is installed on 9k iOS apps and 46k Anrdoid apps (though I highly doubt it, I really think it's much more than that).
This all is rather approximate, but that is the point. It's almost impossible to track down. It sure looks like somebody (AHEM, GOOGLE, AHEM, APPLE) has business interest in this jump through hoops.
Conclusion
You're my cutie pie, you think you know anything about this world? That's the tip of the iceberg I call "Disappointment in IT".

Imagine it's a quest. Your character is the most selfish asshole on the planet and you woke up in the morning knowing you control thousands of sites and apps with hundreds of millions of visitors. You know absolutely everything about them, every single detail.
What can you do about it? Wait for the next article.