Как собирают наши данные
Тяжело быть в IT, потому что все твои школьные друзья вообще не вдупляют, чем ты занимаешься. Программист, продакт-менеджер, QA — чем это всё отличается от починки принтера? (подсказка: за починку принтера не получаешь 300k в секунду).
С обычными людьми об IT и не поговорить, потому что этой индустрией пользуются, но её не понимают. Но есть одна тема, которую можно поднять с любым смертным и которая его заинтересует, которую он поймёт и которая взорвёт ему мозг: приватность данных.

Дисклеймер:
- пост длинный. Но я разбавил его шутейками и картинками, чтобы клиповое мышление не умерло в агонии;
- если вы из айти — ну, штош, считайте, что забрёли в первый класс и изучаете алфавит. Возможно, не узнаете ничего нового; если узнаете — это тревожный звоночек для вашего работодателя.
Как за нами следят? Спасёт ли VPN и режим инкогнито? Может, стоит вообще спаковать манатки и уехать в тайгу жить среди медведей?
Часть 1: Классификация заболеваний
В каком-то смысле право на частную жизнь консолидирует все остальные права: на голосование, свободу самовыражения, равные возможности и так далее. Достаточно потерять право на частную жизнь и всё, тобi пiзда. Большинство людей влёгкую попадает в ловушку мышления "Мне нечего скрывать, какое мне дело до приватности?". Распространённая ошибка. Беспокоиться надо не о том, что ты хочешь скрыть, а о том, что ты даже не думаешь скрывать.
Тема настолько обширная, что пришлось придумать свою категоризацию. Я долго над этим думал (минуты 3, не меньше) и пришёл к такой мысли: самое важное — это очевидность того, кто хранит данные пользователя, что это за данные и как ими манипулируют. Выходит три переменных: актор, данные, манипуляция. Всего-то трёхмерная матрица — помните, я писал, что даже тупой поймёт суть статьи? Не помните? Я тоже. Видимо, не писал.
Актор:
- непосредственный получатель. Когда вы отдаёте свой номер телефона для получения очередной скидочной карты, магазин получает ваш номер телефона. Да, первый невозможный инсайд из статьи, спасибо, Даня — не за что, дорогой читатель.
- теневой получатель. Но так ли очевидно, что при получении скидочной карты вы соглашаетесь на передачу и продажу этих персональных данных кому угодно? Хотели бы вы, чтоб Google и Facebook знали, что у вас есть карта постоянного покупателя борделя "Упругий бутон"? А ведь они эту хуйню несомненно купят. Вы еще даже не скачали с торрентов "Он вам не Димон", а отдел "К" уже пробивает, какую туалетку вы покупаете, чтобы на ней шрифтом Брайля передать угрозы вашей жопе, всё спасибо скидочной карте "Ашана".
Данные:
- то, что вы сознательно отдаёте. Вы открываете очередное приложение, которое добавляет вашей морде ушки няшного кокер-спаниеля. Оно просит доступ к галерее и камере, вы, разумеется, согласие даёте. Что может пойти не так?
- то, что вы не хотели бы отдавать. Ммм, 3896 фотографии, снятые за 3 года. Забавно, что эти фотографии среди прочего содержат гео-метки с точными координатами места кадра — это же, выходит, точная история всех ваших перемещений за это время? Кто б знал, что приложение получает программный доступ не только к тому кадру, который вы выбираете, но и к всем другим.
Манипуляция:
- хранение. Возвратимся к аналогии с фотографиями: если вы выбираете фотку для добавления пёсьей морды, она может храниться на серверах сервиса добавления пёсьих морд произвольное время. Ничего необычного.
- вычисление. Но, как я уже сказал, помимо одной загруженной фотки, приложение будет иметь доступ к всей галерее. Так ли очевидно, что по элементарному анализу времени съёмки всех кадров можно найти адрес вашей работы/учёбы и дома? А что всю галерею можно прогнать через машинный алгоритм поиска порно-изображений, чтоб аккуратненько залить только ваши нудесы на сервера? Надеюсь, собачья морда того стоила.
- продажа. "Если ты не платишь за продукт, ты и есть продукт". Instagram бесплатен только потому, что любой человек в мире может за мизерный бакшиш показать рекламное объявление только своей узкой аудитории. Кто часто путешествует в страны с пляжным отдыхом, или кто любит определённую еду, или у кого высокий доход. Instagram это вычисляет из огромного объёма собранных данных, а рекламодатель может эти сегменты комбинировать как угодно; разумеется, когда вы кликаете на рекламу, рекламодатель точно знает все характеристики, под которые вы подходите. Такие дела.

- взлом или слив. Ой, посоны и посонессы, когда до этого дойдём, я специально включу камеру на вашем ноуте, чтобы заснять охуевшее лицо. Пока просто поверьте: данные теряют абсолютно все, от гаражного стартапа до Google, от районной бухгалтерской конторы до Федеральной Налоговой Службы целого государства. От некоторых случаев у меня ходят мурашки по телу.
Некоторые из пунктов так и просят какого-то объяснения (и оно будет!), потому что у неокрепших умов пользователей почему-то возникает мысль, что Большие Корпорации не такие уж плохие и точно желают человечеству добра. Штош, если вы так тоже думаете, разочарование будет болезненным.
Часть 2: Акторы
Начнём сверху вниз. Комплюктеры связываются между собой по Великой Интернет-Сети, а общаются они с помощью Волшебных Запросов. Поэтому, чтобы понять угрозы, сперва разберём то, как работает Волшебный Запрос.
(всё это реальные термины, я профессионал, верьте мне)
Когда вы заходите на чей-то блог, ваш компьютер совершает запрос к другому компьютеру и получает какой-то ответ. Но запрос не идёт линейно к целевой машине, а проходит через несколько промежуточных пунктов. На каждом из этих промежуточных пунктов нас подстерегают опасности.
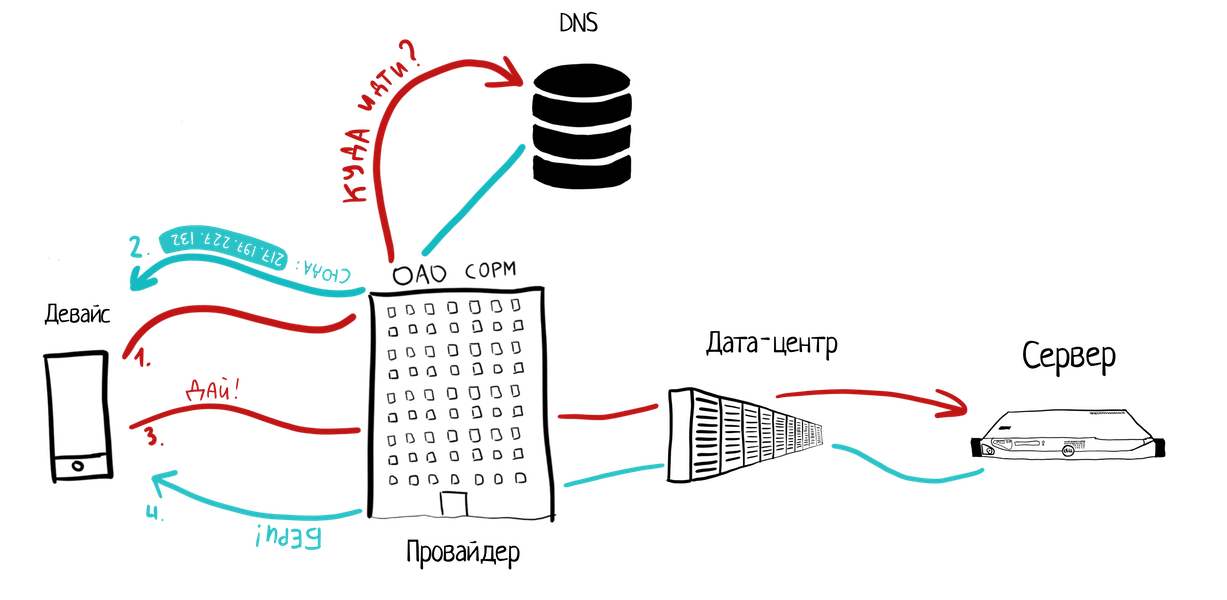
Схема суперпростая, её соответствие реальности — где-то 60%, но и вы, если верить британским учёным, на 60% банан, так что интересующиеся могут почитать матчасть.
Девайс → DNS
Машины привыкли между собой адресовать запросы по так называемым ip-адресам — выглядят они как четыре числа, разделённые точками, например 127.0.0.1. Люди же привыкли пользоваться буквенными, понятными нашему аналоговому мозгу — например, dkzlv.com. Это мы называем доменом.
Ещё хоть один чёрт придёт ко мне в личку с рассказом про ipv6, я за себя не ручаюсь.
Всё это удобство благодаря штуке под названием DNS (Domain Name Server, Домен Имя Сервер, понятно всё?). Думайте об этом как об огромной таблице в Excel, которая переводит домен в ip-адрес. Мой — 127.0.0.1 (РКН, баньте, я не против).
Вот мы и узнали первую течь: DNS. Проблема в том, что отцы-основатели интернета не предвидели информационную революцию, и обмен данными с DNS они сделали без какого-либо шифрования. О шифровании канала мы поговорим попозже, но суть проста: ваш провайдер всегда будет знать, какие сайты вы посещаете, и частенько может через модификацию ответа подредактировать данные, приходящие от DNS (если владелец сайта не озаботился DNSSEC). Так сейчас работают все DNS по умолчанию.
Отвечу на ваш вопрос: да, ваш провайдер знает, что вы хотите на тот сайт, мысль о котором вызывает струйку холодного пота по вашей спине.
Решение: их есть несколько у рыночка. Вам подойдёт любое из двух: DNS-over-HTTPS (DoH) и DNS-over-TLS (DoT), разницу понимают только бородатые умные сисадмины, а нам не стоит вскрывать эту тему, мы молоды, нам всё легко.
Помните, безрукие спецы вашего провайдера что-то настроили и дали вам бумажку со словами "только не потеряйте"? Бумажку вы тогда выбросили сразу, конечно же, И ПРАВИЛЬНО СДЕЛАЛИ. Среди прочего на ней был написан DNS вашего провайдера, который вам силком настроили. "Для скорости" — говорят они, "небезопасное говно" — читаем мы. Они однозначно не поддерживают DoT и вряд ли когда-нибудь будут, потому что тогда и блокировать сложнее, и данные о вас не пособираешь.
Используйте независимые современные DNS-сервера. Я рекомендую использовать DNS Cloudflare с крутым адресом: 1.1.1.1. Он бесплатный, быстрый, а еще обещают "zero-logs policy", то есть не сохранять ничего о ваших мерзких секретиках. У них есть приложения для мобилок, которые всё настраивают сами и магией, лучше пользуйтесь ими, иначе будет сложно.
Для десктопа всё чуть запарнее. Сперва надо установить DNS на уровне системы, а потом включить "экспериментальную" функцию DoH в браузере. Инглиш онли, сорри.
Девайс → провайдер → ДЦ → сервер
Есть два типа соединений: защищённое и незащищённое. О незащищённых вам сообщит браузер, если он у вас не древний как говно мамонта. Если он примерно как последнее говно вымершего в 2013 году чёрного носорога, то даже настоятельно попросит одуматься и не пользоваться таким сайтом.
Если видите сообщение про незащищённое соединение, лучше вообще закрыть страницу и ничего с ней не делать. Поверьте, с точки зрения информационной безопасности это хуже, чем заниматься незащищённым сексом с партнёром, у которого от гениталий расходятся радиальные красные полосы.

При незащищённом соединении нет никаких уязвимостей, кроме одной небольшой: любой посредник имеет полный контроль над всем, что вы принимаете или посылаете, то есть это полное отсутствие безопасности. Мобильные операторы, например, вставляют на незащищённые сайты свою полноэкранную рекламу без ведома владельца сайта.
Так что поговорим про защищённое соединение. Чтобы вы могли блеснуть перед бабушками у подъезда знаниями, дам краткий ликбез в криптографию (нет, с криптовалютами не связано) и работу сети.
Если вы не PhD по криптографии и не запускали из школьной столовки свои ICO, достаточно знать, что существует два типа шифрования: симметричное и асимметричное. По-простому, в симметричном для шифрования и расшифровки используется одинаковый ключ. В асимметричном одним ключом вы зашифровываете — его часто называют публичным или открытым — а вторым ключом расшифровываете — его называют приватным или закрытым.
Никто не знает, какая там математика замешана (как никто не знает, почему такие на вид тяжёлые самолёты летят по небу), но протокол Диффи-Хеллмана, лежащий в основе всей этой магии, достаточно безопасен, чтоб не бояться посылать своей семье сакральные фотографии котов.
Вот для защищённого соединения используются оба типа шифрования. Чтоб вы не заснули, я оформил эту процедуру в виде пьесы.
Действующие лица:
Озгюр: молодой турок, которого женщины мира единогласно решили воздержать от секса.
Нина: русская девушка, которую я добавил сюда для полноты картины.
Телефон Озгюра: устройство, отправляющее сообщения.
Tinder: сервис, где принято писать похабные сообщения.
Сервер Tinder: сервер, принимающий сообщения.
Акт 1
Озгюр долго печатает Нине в Tinder
Телефон Озгюра (обращается к серверу Tinder): Дарова, брат. Этот чел хочет написать еще одно сообщение. Давай сделаем всё по-чистому, защищённо. Я умею в HTTPS.
Сервер Tinder: Дарова, брат. Понятно, соболезную. Я тоже в умею в HTTPS. План такой, короче: во-первых, я тебе пришлю мой публичный ключ, и все дальнейшие сообщения ты будешь шифровать им, чтоб нас никто не подслушивал. Во-вторых, пришли мне какую-нибудь в зашифрованном виде белиберду, чтобы я на её основе сделал симметричный ключ. Ведь симметричное шифрование, дорогой читатель, работает намного быстрее асимметричного.
Четвертая стена рушится
Сервер Tinder присылает публичный ключ
Телефон Озгюра и Сервер Tinder жмут руки
Телефон Озгюра: Твой публичный ключ хорош. Лады, вот тебе моя белиберда. Я из этой белиберды сгенерировал себе симметричный ключ. Выглядит он примерно так.
Телефон Озгюра присылает зашифрованную белиберду и примерный вид ключа
Сервер Tinder: Ок, я смог расшифровать, и правда херня какая-то. Окей, я на её основе тоже сгенерировал симметричный ключ, и то, что у меня вышло, выглядит так же, как у тебя. Значит всё ок? Я кончил.
Телефон Озгюра: Я тоже кончил.
Всё дальнейшее общение Телефон Озгюра и Сервер Tinder шифруют одинаковым симметричным ключом, который в чистом виде по незащищённому каналу не посылался
Акт 2
Озгюр (закончил печатать): даш писку ебат.
Конец
Некоторые детали я для простоты опустил (центры сертификации, хэши симметричного ключа и т.д.). Особо заинтересованные нёрды могут почитать про TLS handshake всё в той же статье про работу сети.

При защищённом соединении все посредники всё равно видят, на какой сервер вы обращаетесь (ip-адрес), но этой информации мало для сколь угодно нормального анализа, поскольку весь информационный поток зашифрован для каждого пользователя индивидуально, потому что симметричный ключ у всех разный. Наверняка есть какие-то сложные и неточные эвристики для определения хотя бы типа контента — например, если ты уже 10 минут что-то качаешь с pornhub.com, скорее всего, провайдер знает, что это схемы для вязания крючком — но о них беспокоиться не стоит, они очень примерные.
Решение: помните про незащищённый секс незащищённое соединение, там всё идет чистым текстом: данные карт, контент, адреса, поля формы, фотографии… Увидите плашку — просто закройте сайт. В 2020 (AND RISING) году просто стыдно не уметь в HTTPS, считайте, что вас по умолчанию такие сайты хотят обуть — глядишь, мир станет чуть безопаснее.
Ежели не хочется, чтобы промежуточные цепочки знали даже про ip-адрес (или если хотите, чтобы РКН лососнул тунца с своими всратыми блокировками), тут как раз и поможет VPN. В моей любимой стране запрещено публиковать инструкции к настройке VPN. Но РКН мне, конечно, не указ, поэтому скажу, что Cloudflare в том приложении, которое я нагло прорекламировал, предлагает и бесплатный VPN тоже. Но лучше все яйца в одну корзину не класть, так что дальше идите к забаненным в России Tunnelbear и пользуйтесь ими, работают как часы. Вертите РКН на что там у вас между ног, не важно.
Итоговая страница → ???
А вот теперь мы подходим к самой страшной части моего опуса. Всё, происходившее до этого момента — это шутки-мишутки, потому что именно на этой стадии нас ждёт минное поле в четыре слоя. Даже лучшие из нас на этой стадии обсираются на постоянной основе.
Как вы уже могли догадаться, магии в комплюктерах нет. Если вскрыть этот гнойный нарыв, за каждым небезопасным и тупым на первый взгляд решением мы всегда найдём добрую и красивую мотивацию. Примерно как было с ядерной энергетикой, все прелести которой жители двух крупных японских городов особо оценили в 1945 году, на 2 ядерных гриба из 5.
За любым общением двух машин стоят запросы. Отправка ваших нудесов незнакомцам в интернете — это тоже общение, даже если это за вас автоматически без вашего ведома делает программа. И с итоговой страницей, которая показывается в браузере, самая большая проблема в том, что она умеет эти запросы тоже отправлять.
Анатомия запроса
Как мы узнали, всё общение между компьютерами — это запросы. Вот ты пришёл на "корневой путь" — например, https://dkzlv.com/ — и это один запрос. А если хочешь перейти на страницу конкретного поста — например, https://dkzlv.com/ru/posts/kak-sobirayut-dannye — это уже второй, свой, отдельный запрос.
Раньше запросы связать между собой нельзя было, то есть не было идентификации пользователей. В те бородатые годы ребята поняли, что нужно придумать костыль, который позволит клиенту между запросами сохранять состояние корзины покупок в интернет-магазине. Как обычно, благими намерениями вымощена дорога в ад. Тогда и были придуманы те самые cookies, о которых в последние годы нас постоянно предупреждают сайты.
Cookies, кукис, печеньки — это по сути большущая строка текста, которая содержит пары ключ-значение и выглядит примерно так:
TOKEN=0d8152ec62c144bdbe9c96e366112aca; FAV_PRON_GENRES=4,8,15,16,23,42; CHECKOUT_STATE=0;
Было решено, что сервер может просить браузер сохранять эту строчку текста в отношении к конкретному хосту, и когда браузер посылает все дальнейшие запросы, он обязуется прикладывать к запросу сохранённые кукисы. Процедура простая:
- вы вводите логин и пароль на сайте очередного стартапа по производству диоптральных очков для черепах;
- сервер проверяет, что всё ок, придумывает несуразную и уникальную строчку текста (вроде
7d8921806f9b4d3baec79c489237acfa), и запоминает, что тот, кто знает эту секретную строчку текста, тот вы; - эту строчку сервер просит браузер запомнить в виде кукис;
- все дальнейшие запросы на этот сайт браузер шлёт с этой строчкой.
Ура! Мы имеем однозначную и безошибочную идентификацию, и состояние корзины не сбрасывается между запросами. Проблема решена, да, но шрапнелью зацепило и нашу приватность.
Так в какой момент Google узнаёт о ваших бессмысленных покупах в интернете? Сейчас разберёмся — мы переходим к стадии галопирующего роста интернет-рекламы.
JavaScript и динамизм
На заре интернетов страницы были статичные. Нажатие каждой кнопки или ссылки приводило к полной перезагрузке страницы. Не было никаких анимаций. Не было баннеров. Не было автоматически воспроизводящих музыку плейеров. Не было таких блогов, что у тебя от анимаций взлетал свеженький Macbook Pro. Знаете, прекрасные были времена.
Но ребята придумали добавить динамизм. Динамизм невозможен без какого-нибудь языка программирования, поэтому для браузеров придумали и стандартизовали лучший язык программирования — Cmm CEnvi Mocha LiveScript JScript JavaScript (потребовалось чуть больше одной попытки, чтобы создать совершенство). JS даёт тот самый динамизм. Что это такое? Например, вот, нажмите на эту кнопку:
К слову про блоги с анимациями, лол. Вот тогда, давным давно, еще в прошлом тысячелетии, такого прекрасного динамизма не было, а тут сразу видно, что изобретение пошло на пользу.
JavaScript — это полноценный язык программирования, и на каждой странице любому разработчику много чего доступно. Без вашего разрешения он может посылать запросы на любые сервера в мире (с некоторыми оговорками), хранить в браузере между открытиями страницы кучу информации, обращаться к акселерометру и гироскопу, следить за всеми нажатиями клавиш на клавиатуре. С разрешением — слать пуши, читать геолокацию, работать с вашими файлами, USB-портами, Bluetooth, считывать данные с камеры и микрофона. Словом, кучу всего, смотрите здесь.
У браузеров, как это часто и случается, есть корявые способы "защиты" пользователя, но не забываем, разработчикам браузеров в сущности немного насрать на вашу приватность, поэтому многие меры защиты обходятся всеми, у кого на месте мозг.

В браузерах даже есть мера защиты, которая не позволяет устанавливать т.н. third-party cookies, то есть куки не с текущего домена. Отправлю вот сейчас из вашего браузера с своей страницы dkzlv.com запрос на google.com, так куки-ж не установятся и не считаются — защита ☝️ Только вот все трекинговые скрипты эти самые third-party cookies не устанавливают, а за каждым вашим пуком в сети следят. Обходной путь-то проще пареной репы (для пытливых — объяснение механизма, автор ответа не дожал, с помощью iframe и верной настройки CORS можно обойти запрет, будто бы его и нет вовсе).
Или вот впаривают они вам, дескать, если есть у тебя, дружище, тёмные делишки (читаем между строк: хотите подрочить на инцест-порно), тогда используй инкогнито-режим! Ага. Это защитит. Режим полной защиты активирован.
У нас у всех есть отпечатки пальцев. И хотя дактилоскопия не настолько точна, как мы привыкли полагать, она всё равно помогает в какой-то идентификации. У наших девайсов тоже в каком-то смысле есть отпечатки. 2 факта:
- я уже говорил, что такое ip-адрес. У вашего устройства (а скорее квартиры, если вы дома) от тоже есть! Помните, все запросы, заходите вы из Chrome или Firefox, в инкогнито или обычном режиме, палят ваш ip-адрес. Из ip-адреса часто можно узнать не просто страну или город, но даже район, в котором вы находитесь. Думали, шутка "вычислю тебя по ip!!1" не имеет под собой ничего?
- ваш браузер выдаёт очень, очень много информации. По отдельности она абсолютно бесполезна: размер окна и экрана устройства, версия браузера, операционная система, дефолтная раскладка клавиатуры, предпочитаемые языки, установленные шрифты и многое другое.
По отдельности бесполезна, но соединив воедино мы получим высокую уникальность устройств. Без ip-адреса ваш конкретный ноутбук может обладать уникальностью 1 на 202k устройств (такой результат у моего ноута, fuck my life, надо перестать устанавливать все прикольные шрифты). С ip-адресом эта уникальность, в общем-то, зашкаливает. Дома у вас, например, ip-адрес почти всегда статический (неизменяемый) и уникальный на квартиру. Поверь, для гугла соотнести вас и вас в инкогнито-режиме просто как для грудничка обосраться.

DEMO-TIME. Идею я беспардонно забрал отсюда. Ребята, как это обычно у айтишников, могут в технологии, но не могут в красивую демонстрацию. Но и у них есть кое-что интересное: они вам покажут все данные, которые ваш браузер отдаёт любому JS-скрипту, а также какой объём идентификационных данных получилось достать и насколько он в сумме уникален. Мне такое лень делать, честно. Но я сделал другое!
Давайте проведём эксперимент. Я обычный ПТУшник без вышки, я не ровня смузи-инженерам из Google. Давай я попробую вас идентифицировать в инкогнито-режиме. Эксперимент простой:
- я задам вам простенький нестыдный вопрос, а вы на него честно ответьте;
- потом — сразу или через какое-то время, как хотите — откройте эту же страницу в инкогнито-режиме (Правая клавиша мыши/Открыть в инкогнито-режиме);
- вы главное верьте: инкогнито-режим же не ПТУшники программировали, а смузи-инженеры, они-то о вашей безопасности думают денно и нощно, инкогнито-режим вас защитит.
Дополнительная подводка:
- для массовки я уже добавил туда 10k отпечатков с разными ответами;
- данные я обнуляю каждый день в полночь по Гринвичу;
- конечно, данные никуда не уйдут. Что происходит в Лас-Вегасе, попадает всего лишь в ширпотребные комедии.
А теперь к самому вопросу!
Признайся, киса, какой у тебя любимый жанр порно?
Я использую тут штуку из открытого доступа, у этих же ребят есть коммерческий продукт, который даёт по их словам 99.95% попаданий (там есть похожая демка, рекомендую).
Хрен знает, сработало у вас моё демо или нет, но у меня работает безотказно. Вот так, друзья, и начинают носить шапочку из фольги.
Скрипты
Скрипты. Скрипты везде. Скрипты в твоём телефоне, в холодильнике и телевизоре, в вибраторе и духовке, в автоматической оконной роллете и ротационном рекламном баннере, в поезде метро и опять в вибраторе. Они везде. В моём блоге тоже.
Чтобы понять важность скриптов для этой темы, надо понять историю развития интернета. Пристегнитесь, вас ожидает путешествие в начало нулевых.
Настроимся.
Меню на картинках. Комик санс как основной шрифт сайта. Уютное потрескивание модема. Интернет по карточкам. Крик мамы из кухни, что ей надо поговорить с подругой по телефону, так что "закрывай свой интернет". Почта на Рамблере, Апорт — главный поисковик. Домашняя страничка на "Народе". Красивый пятизнак как статусный предмет. Ты пьёшь пиво за школой с ребятами, твоя жизнь совсем беззаботна.
Настроились.
Каталоги
До повальной адаптации поисковиков существовали каталоги. Ну вот открыли вы браузер в 1998 году, куда идти, что делать? Гугла в текущем огромном виде пока нет. Правильно, надо идти в каталоги. Это были модерируемые людьми наборы сайтов, на которых вы могли узнать, где стоит почитать, чо там у хохлов, а где можно поиграть в онлайн-нарды с онлайн-армянами. Каталоги создавались когда-то крутыми интернет-компаниями (олды тут? помните какими гигантами были Yahoo и Rambler?) и ими же модерировались.
Опираться чисто на человеческое мнение невозможно, нужны данные. Как понять, что сайт из каталога реально популярен? Вот чтобы как-то сортировать их по популярности, создатели каталогов придумали счётчики. Для конечного юзера это просто картинка на сайте, но дьявол в деталях:
- все картинки в вебе скачиваются отдельно от самой страницы, это подключаемые внешние ресурсы.
- если это внешние ресурсы, то и их скачивание — это некий отдельный запрос.
Конечный юзер видит просто картинку с количеством уникальных посетителей и количеством запросов; а вот каталог, который эту картинку генерирует, видит всё про вас: когда зашли, с какой страницы и, конечно, может вас идентифицировать между разными сайтами. Для такого дела нужно было содействие создателей сайтов, и уже тогда они продали вас с потрохами: им предложили суперпростую аналитику (как раз на уровне просмотра количества посетителей сайта) и позиции повыше в каталоге, если у них популярный сайт, то есть больше посетителей. Всё, вы в жопе, каталог знает, что у вас есть фетиш на нарды с армянами. Счётчик стоит на сайтах, каталог получает аналитику и автоматически двигает популярные сайты вверх, а непопулярные — вниз.
Важно, впрочем, понять, что картинка — это статичный ресурс. Чтобы скачать картинку нужен запрос, да, но между посещениями одинаковых страниц картинка сохранялась браузером (чтоб не запрашивать еще раз то, что не изменилось), а, значит, каталог получал инфу даже не обо всех посещениях, не говоря уже о поведении на странице: сколько времени провёл на странице, как внимательно читал, какие кнопки жал и насколько глубоко по сайту походил. На то это и примитивная картинка, а не скрипт.
Поисковики
Потом пришли поисковики, и всё стало внезапно сложнее. Поисковик автоматизированно посещает сайты, скачивает все страницы и осуществляет по ним поиск. Главный вопрос такой: как ему понять, что из 20М страниц по запросу "как совиршить суецыд" он посоветовал самый лучший результат? Ответ: в идеале пользователь должен пропасть с радаров. В отличие от каталога, он не знает, как себя ведёт пользователь на странице, не знает, как часто тот туда приходит, ему не на что опираться. Тогда Google и пришёл к абсолютно гениальному решению.
Счётчики отпадают — не так-то и много данных они дают. Значит нужен скрипт, и нужно его встроить и максимум сайтов мира. Как без шантажа и паяльника заставить вебмастера (тоже термин из прошлого) встроить в свой сайт сторонний скрипт? Дать что-то сверхинтересное для разработчика. В 2003 году они запустили AdSense — свою площадку для размещаемой контекстной рекламы. Эта площадка позволяла разработчику сайта зарабатывать с просмотров баннеров на своём сайте, достаточно было только разместить один малюсенький скрипт. Маленький шаг для компании, огромный пиздос для человечества.
Вторым шагом был запуск Google Analytics. Помимо денег все разработчики хотели всё больше и больше знать о том, как пользователи ведут себя на сайтах: какие страницы посещают, сколько там проводят времени, как быстро и в каких направлениях отваливаются. Google запустил бесплатный сервис веб-аналитики для всех: "просто вставь мой скрипт, пожалуйста, делай, я хочу обмазаться твоими данными" — томно дышал бигдатой на ухо Google всем разработчикам вокруг, бесцеремонно лапая их за сервера.

Как мы выяснили, скрипты могут знать всё: на что кликаешь, как далеко скроллишь, куда идёшь дальше, что вводишь с клавиатуры и так далее. Что может пойти не так?
Вот мы и подошли к заключительной части ужасного опуса.
Так кто этот теневой получатель?
Да кто угодно.
Согласно BuiltWith, из миллиона самых популярных сайтов в мире 68% имеют Google Analytics. Из 10k самых популярных — 88%. У AdSense пенетрация поменьше — 16% и 33% соответственно. Мы все под колпаком, чудило. Знаю, ваши ладошки вспотели, стало страшно и немного спёрло дыхание. Я хочу, чтобы вы, дорогой читатель, обосрались от страха, поэтому сообщу то, чего вы боитесь больше всего: 93% порносайтов имеют встроенные скрипты. Google знает, что вы любите то, что в вашей стране осуждается.
Нет-нет, не поймите меня неверно, Google не единственные, кто шалит с данными. 40% топ 10k сайтов имеют трекинговый скрипт Facebook.
Automattic (компания, о которой вы вообще никогда не слышали) разработала движок Wordpress, они же предлагают у себя этот сайт разместить; суммарная посещаемость — полмиллиарда человек в месяц; а недавно они еще купили эротический блог-хостинг Tumblr, у которых в начале 2019 было 437М посетителей.
Видите крутую плавающую кнопку с лайками поста? Это может быть скрипт ребят из AddThis, у которых 26% из топ 10k сайтов.
Видите красивые стильные иконки на сайте? Есть вероятность, что на сайте стоит скрипт FontAwesome, встроенный на 46% тех же сайтов.
У всех этих компаний есть Privacy Policy, в которой написано много разного буллшита, который владельцы сайтов и тем более посетители никогда не читают. Часто там могут быть абсолютно дикие вещи — вроде того, что популярное браузерное расширение Grammarly, которое проверяет орфографию текста, хранит весь вводимый тобой текст вечно, сотрудники могут его читать, а также они как компания получают неэксклюзивное право на хранение, использование и копирование текста. Я это не придумал. Справедливости ради, саппорт Grammarly в треде постарался объяснить многое, но когда ребята пишут "да, написано так, но на самом деле мы это не делаем", я тихонько хихикаю в кулак и надеваю шапочку из фольги.
Вы всего этого не знаете, не видите, а оно так. Все о вас всё знают.

Решение
Ты пока не знаешь, почему весь этот сбор данных плох, но, просто поверь, что ты бы хотел его остановить. Он не в твоих интересах.
Я вижу несколько вариантов. Самый простой и пока работающий сейчас — пользоваться браузером Brave. Он по сути идентичен браузеру Chrome, только в нём нет рук Google, это частная компания, во главе, кстати, с одним из создателей языка JavaScript, Бренданом Эйхом. Плюсов несколько:
- в браузер встроен хороший блокировщик всего этого описанного дерьма. Это не гарантирует тебе защиту от трекеров, и некоторые данные всё равно будут утекать, но кратно, кратно меньше;
- у браузера открытый исходный код, то есть ты можешь пойти и почитать код браузера. В идеале это значит, что в него не получится встроить говна, не обратив на это внимание сообщества.
Молю, не пользуйся расширениями в браузере. Это полная дыра, об этом еще будет пост.
Как же приложения?
Я осознанно опустил в статье всё, связанное с обычными приложениями на смартфоны. Там всё кратно хуже, приватности просто нет как категории:
- без специального софта нет способа запретить приложению доступ в сеть целиком или избирательно. Да, на Android есть отдельное разрешение на работу с сетью, но, по субъективному ощущению, его запрашивают тупо все приложения. В вебе это даёт делать браузер;
- без специального софта нет способа посмотреть состав запросов, которые приложение посылает; если установить этот софт (Charles, например), приложение может это узнать (читайте про HPKP), а, значит, может перестать заниматься грязью. Более того, некоторые приложения отдельно запрещают использование такого софта, прямо отказываются с ним работать (привет, Фейсбук!). В вебе это можно делать в любом браузере в консоли разработчика в вкладке Network;
- приложения на iOS, Linux, Mac и Windows компилируются в нечитаемый байткод, а приложения на Android видоизменяются до почти что нечитаемого состояния. Узнать, что происходит внутри приложения практически невозможно или безумно сложно. JavaScript, например, в вполне читаемом виде приходит к вам на устройство;
- всем приложениям без разбора доступна высокоточная идентификация клиента по рекламному ID. Идентификация работает между приложениями. В вебе нет рекламных ID, но идентификация между сайтами существует;
- обе самых популярных платформы принадлежат техногигантам, которые, как мы выяснили выше, не очень заинтересованы в сохранении приватности. Официально веб никому не принадлежит, в реальности — им владеет обширный конгломерат корпораций и государственных организаций, которые следят друг на другом и мешают всем заполучить неконкурентное преимущество — выигрывают юзеры;
- приложения имеют возможность в тихом режиме запускаться в фоне без вашего ведома и делать хрен знает что вообще. В вебе это пока почти невозможно, но зачатки технологий есть.
Приложения еще более закрыты и еще больше подтвержены этим загнивающим практикам мониторинга пользователей.
Кое-какой ресерч, несмотря на все сложности, всё же возможен. Есть ребята 42matters, у них есть бесплатная триалка с возможностью посмотреть, кто использует определённые SDK (читай, те самые скрипты). Например, SDK Firebase (это продукт Google) установлен у 25k приложений на iOS и 1.3M на Android, включая Pinterest, Shazam и Google Maps. SDK Facebook стоит у 81k приложений на iOS и 383k на Android, включая Spotify, Instagram, Lyft и Clash of Clans. SDK Appsflyer, которое помогает точно идентифицировать тебя, стоит у 9k приложений на iOS и 46k на Android (хотя тут у меня сомнения, по субъективному ощущению намного больше).
Данные неточные, но в том-то и смысл, что отследить это очень сложно. Проблема с сбором данных имеется и тут, только по этой проблеме еще меньше информации и исследований. Словно бы у кого-то (КХЕ-КХЕ, ГУГЛ, КХА-КХА, ЭППЛ) есть бизнес-интерес вставлять эти палки в колёса.
Заключение
Наивный мой пирожочек, вы полагаете, что знаете хоть что-нибудь в этом мире? Вы еще даже не у входа в заветную пещеру наслаждения, вы как Тарантино, только пальцы ног пососали. Самое сладенькое будет дальше.

Представьте, что это квест. Вы — самый корыстный мудак/мудакесса на планете, и вы проснулись утром, узнав, что контролируете тысячи сайтов и приложений с сотнями миллионов посетителей. Вы хотите узнать ну абсолютно всё, всю грязнющую грязь о них.
Как и, главное, что можно узнать из всего этого? Разберём в следующей статье.